Energy has become a headline topic in Europe and Germany, primarily because of high prices and supply uncertainty. I will not rant about how the dependency on single suppliers with their own political agenda was a terrible mistake, or that we were indifferent about energy sources as long as the price was low, no matter the ecological impact and financing of a fascist regime. I’ll also not go into details how the transformation to cheap renewable energy was procrastinated for at least 20 years to serve lobby groups that love to externalize the cost of fossil fuels to society - in addition to consumers paying a lot of tax on energy.
Whatever you may have heard, Germany is not a role model for the Energiewende and usage of renewables. We still burn gigatons of lignite and hard coal, other countries have a much cleaner mix of energy sources to produce electricity. As long as we burn a single chunk of lignite, Germany is in no position to give energy advice to others.
Anyway, I write this as an example for how technology can be leveraged to improve the economic and ecologic impact of energy consumption, electricity in particular. Perhaps you can use it as food for thought or consider if the project may be useful for you to replicate. I assume that using low-consumption appliances, LED lighting etc. are a given, if not start doing this before optimizing.
As every household, we were faced with rising cost of electricity. It is very common in Germany to use utilities contracts that lock in a certain price per kWh for a certain duration, usually 12 months. Energy suppliers hedge their risk of price changes by using the electricity futures market, rather than buying on the spot market. At least the good ones do, those who didn’t hedge but sell at 30ct while buying at 60ct on the spot market went bust quite early. Our electricity supplier sent a notice that after the end of the 12-month period, our price would rise from 30ct/kWh to 69ct/kWh, just in time when we got our first EV.

Since all suppliers are in a similar situation, there is no real alternative, since others either charge the same price or don’t accept new customers to reduce their risk.
While paying 30ct/kWh may be reasonable under normal market conditions with low price volatility, the new pricing contains lots of uncertainty about price development. We would have essentially locked in that uncertainty for 12 more months. We use a lot of electricity, caused by charging EVs, working from home, operating the IT-homelab and smart-home equipment. In our case, that would have meant a price hike of about €1.500 per year. At the same time, monitoring the spot- and futures market shows that prices are indeed fluctuating a lot. Among other factors, this happens because of the merit-order system used in Europe.
In a nutshell, it is an auctioning system where a given power requirement (say 1000MW for 10:00 to 11:00) is purchased from electricity suppliers and the cheapest energy source goes first. Let’s say there are 500MWh renewables at 3ct/kWh, 200MWh nuclear at 8ct/kWh and 200MWh coal at 10ct/kWh. Unfortunately Germany, and many other countries, chose to rely on natural gas to cover peak load. If the other energy sources are not sufficient, gas power plants are being switched on to cover the spikes. Assume that another 100MWh are provided by natural gas at 100ct/kWh to produce the 1000MWh required. Now the merit-order systems falls apart from the perspective of the consumer. Instead of paying 6ct/kWh for the cheap 90% and 100ct for the remaining 10%, the most expensive part of the mix sets the price for all other constituents - so the consumer pays 100ct/kWh.
In this process, providers of renewable energy earn a large profit since they produce for 3ct/kWh but get paid 100ct/kWh, hence “merit”. Most large electricity producers operate multiple sources of energy, including renewables and natural gas, which means they profit a lot from shortages. This system is totally fine in cases where prices for energy sources are relatively similar, however it creates huge price volatility in cases where single energy sources have extremely high prices. Since adding renewable energy sources was more or less blocked by political initiatives for years, there is little the market can do to actually invest and get rid of gas. Regardless if it’s natural gas no longer arriving via pipeline or expensive LNG shipped around the world - gas pushes up prices a lot. Other countries in Europe have similar issues, so there is no quick way of just purchasing electricity from our neighbors to fill the gaps.
After gathering some background knowledge about the market mechanics, I tried to find a better solution for our electricity supply. One where we don’t pay the risk premium incurred by the electricity provider, and one where we don’t have to reduce power consumption. Advanced societies require lots of energy to develop further - and that’s fine as long as they are sourced sustainably and little gets wasted. Adding solar or other self-generated electricity is unfortunately not an option since we live in an apartment, the grid is the only viable electricity provider.
It turned out however that some electricity providers entered the market which don’t use fixed prices but instead forward spot market prices to their customers, with a small fixed fee to cover their operations. Some of those see themselves as technology companies and offer integrations and APIs to automate stuff based on electricity prices and consumption. That’s why I had a good look at Tibber, which provide 100% renewable energy and have created a nice ecosystem of integrations. Using Tibber Pulse as an addon to our power meter allows per-hour billing, which is a great incentive to use less electricity at peak times. Compared to “actual” smart meters, this addon is a one-time expense and does not require professional installation.
Interested? Sign up using my reflink, we both get €50: https://invite.tibber.com/tjibqpvo
During my research, it became obvious that volatile electricity prices offer a great opportunity for arbitrage, regardless of the absolute price. While there are the typical spikes in the morning and the afternoon, electricity is in fact relatively cheap during the night. Here is a graph of electricity prices at a typical weekend in Germany, price spikes are a lot more pronounced during the week.
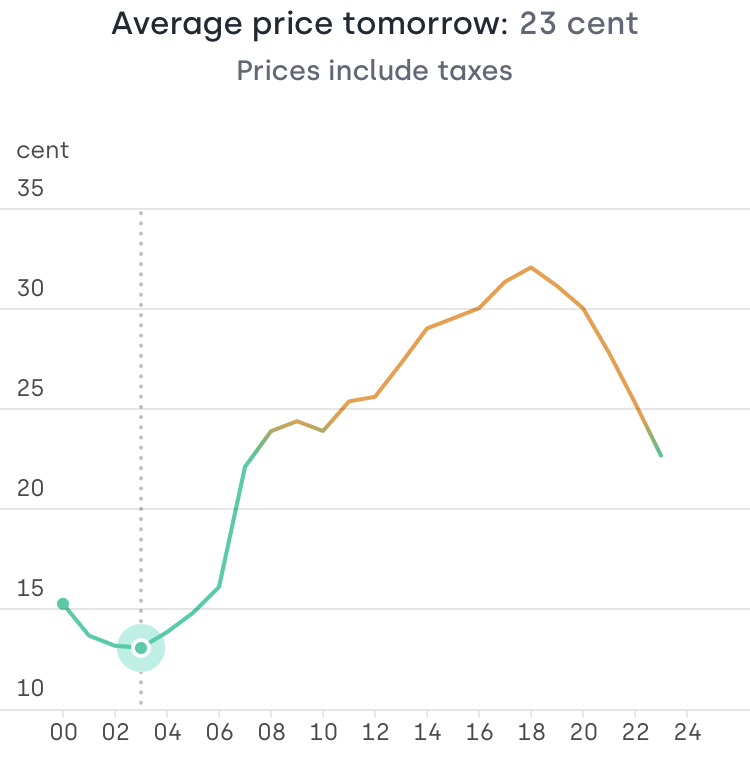
At this day prices spike to about 32ct/kWh but are below 15ct/kWh for multiple hours. Most people pay a fixed price per kWh and just don’t care about peak load. This leads to the need for electricity producers to switch on their expensive natural gas power plants. Not following this trend would save money and help reduce peak load in the grid.
Great, so how can we save money? And how did I manage to make this price chart look like this?
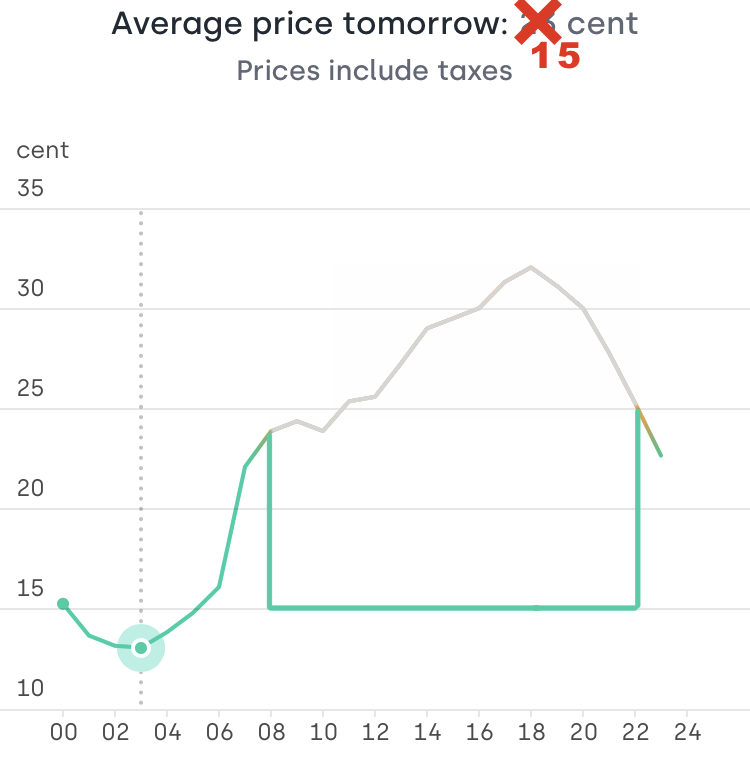
Moving off-peak
Obviously, it makes sense to move some electricity consumption to the night if it is not time sensitive. No - we don’t cook our meals at night, but charging an EV off-peak while power is cheap is entirely possible. Tibber integrates with many Charge Box and EV makers as first-class citizens right at its App. So instead of charging when plugging in, the car will start charging when Tibber tells it to. Since Tibber does not make money with the amount of energy you consume, they don’t care if you use cheap or expensive electricity, either. This is a huge difference to legacy power tariffs and changes economic incentives dramatically.
The same is true for household appliances. In most cases, I don’t care if the dishwasher or the washing machine runs at 17:00 or at 02:00. Modern appliances are “connected” but not directly integrated with Tibber, so I had to build something that takes Tibber price information and triggers the appliances “remote start” abilities when electricity is cheap. I did that with HomeBridge, which comes with many plugins both for Tibber and for smart appliances from Bosch, Miele, Siemens etc. HomeBridge plugins like tibberswitch create events if electricity prices are cheap, those events can then be consumed by your home automation solution, for example HomeKit, to trigger events like “start the dishwasher”.

Our baseline electricity consumption could however not be moved since it does not make sense to turn off the freezer for multiple hours or, behold, even our network infrastructure and home server. Instead of moving consumption to times of low electricity prices, we need to move low electricity prices to times of consumption. Batteries are good at this.
Battery buffer
So I started looking into home power backup solutions. There is a great bunch of solutions and educational content out there, just be careful not to get lured into the prepper/doomer rabbit-hole. Jokes aside, of course this is primarily about saving money, but it can’t hurt to have some kWh of backup power in case of a blackout or the zombie apocalypse. Most solutions are made to store electricity from solar panels and feed it back to individual appliances as AC, like powering your cabin somewhere in the woods where there is no power grid.
With advances in battery technology, there have been some very interesting solutions lately that combine quick charging, good capacity with outstanding durability. Products based on LiFePO4 (“LFP”) batteries can store multiple kWh of electricity in a small package, endure thousands of charging cycles and charge within a few hours. Importantly, LFP batteries are very safe and can be run unsupervised forever without the risk of fire based on malfunction or defects. You can literally shoot those batteries without adverse side effects.
Some brands to watch are EcoFlow, Bluetti and Zendure. Zendure is pretty hard to come by in Europe, and they seem to copy EcoFlow quite a bit. Their focus is much for on “solar” generators, while Bluetti and EcoFlow play the “AC charging” tune a bit more prominent. It felt that Bluetti is not really making an up-to-date device that fits my needs, so I ended up in the EcoFlow ecosystem.
This is a case-study and not a product review, however I will include some kinks and learnings that never get noticed in paid “reviews”. Judging from the number of videos at YouTube, manufacturers sends out hundreds of free review kits. The only reviews I can recommend are the ones where people are taking the device apart and check for actual build quality and engineering decisions rather than reading a feature list. All was paid for with own money and I did not take any incentives. Note that all this relates to a 230V/50Hz grid and “EU versions” of devices.
Exploring the ecosystem
First, I had a look at the EcoFlow Delta Pro, which is a behemoth of a “portable” battery. It certainly fills a niche that is left by “true” home battery solutions from BYD, Tesla, E3DC and others. But since I did not plan to re-wire my home grid for battery backup and all the effort would not really pay off financially, I went for the much smaller and economical EcoFlow Delta 2 instead. You can read all the specs on their website, they are correct, I won’t repeat them here.
While reducing our power consumption, I identified that there are just two major appliances left, which continuously use power. A deep freezer and our home server rack. Since those have very predictable power usage profiles, they are the optimal candidates to start gathering experience with battery buffer. Both devices are located in the same room, so infrastructure changes would be minimal.
The Delta 2 has a 1kWh LFP battery built in and can be connected with an extra 1kWh LFP battery to a max capacity of 2kWh for about €1850 all-inclusive. It can also be connected to the 2kWH “Delta Max” extra battery for 3kWh of total capacity. However, that older NMC-based battery will just support ~800 charging cycles before reaching 80% capacity.
Just to mention one downside of EcoFlows expansion system: The connection plug is on the side of the devices and the proprietary plug is not angled and has a very inflexible cable. This is a super inconvenient placement if you use the Delta 2 at any space-constrained area, since you already need a gap for airflow on both sides. Please EcoFlow, put that port to the front or the back or at least offer an angled connector that creates a flush connection!
Usage considerations
The freezer and the rack consume a combined 120W, which means 2kWh is already plenty to cover 14 expensive hours of electricity. It also leaves enough time to charge the batteries with a gentle 300W. The Delta 2 can actually charge at 1200W (1500W with extra battery) but that can’t be good for longevity and efficiency. After all, I’m trying to get as much capacity out of this thing as possible - 2kWh x 365days x 10years.
With the latest firmware updates, the Delta 2 is very quiet when charging or delivering less than 500W. The 1.0 firmware apparently had no fan management built in. Out of the box, it was so loud (easily 60db) that it would disqualify the Delta 2 for in-home use. Luckily, that got patched. Talking about firmware, updating it does usually interrupt AC output. That needs to be taken into consideration when using it as power supply for sensitive devices.
UPS feature
The Delta 2 does bypass AC power while being connected to the grid and only switches to the inverter if the grid power supply fails. That is pretty much what basic UPSs do. EcoFlow actually advertises this feature, but is not very vocal about switching times and compatibility to computers. If switching times are too slow, the connected devices will suffer a brief power outage and restart. A proper double-conversion online-UPS requires 0ms to switch from mains to battery, which means any device connected to the UPS will not even notice that it has switched. Cheaper “line interactive” UPSs require 10-20ms to switch over. The ATX standard requires switching times of about 15ms and many servers will require even lower switching times.
It turns out that the Delta 2 can switch quick enough depending on its load. Switching while being loaded with 600W did not work for my setup, but when only being loaded with 120W the switching time is low enough to keep my home server and network equipment running. Cool! Producing the cleanest sine-wave I have ever seen out of a consumer-product inverter certainly helps.
Efficiency
With 2kWh of capacity and 120W continuous load, one would expect about 17h of runtime. Of course all the electronics of the battery (BMS, WiFi, Inverter…) take an efficiency toll. I found that the Delta 2 is using about 12W continuously while charging and providing AC at 120W through its bypass. 90% output efficiency is a good number for a portable device, especially for such low-power usage considering its beefy 1800W inverter. Input efficiency is about 90% as well, you need to charge 1200Wh at 300W to max out the 1024Wh battery. Many devices are most efficient at 50% load with a bias to the top, you don’t buy a 1000W device if you just plan to just use a fraction of that. The EcoFlow Delta 2 appears to be very well-balanced to serve all ends of the spectrum, though.
Automation
EcoFlow recently started adding basic automation capabilities to their app and labeled them as “lab features”. They are exactly as buggy as that sounds. Until they become more usable, I’m resorting to external automation to control battery charging. For now, that’s an Eve Energy plug, which gets switched on and off based on time of day to trigger the UPS function and switch back to charging the battery. I could create automation that factors in energy prices, but I don’t think it is worth it. Energy prices are just one factor, each charging cycle also translates to costs for battery lifetime and the concept of “scalping” only works if there is a large enough difference in price that offsets electrical inefficiencies. That’s almost never the case during the day. Simplicity beats overly complex solutions every time.
Guesstimates
One thing that really struck me is the estimate - or rather guesstimate - for remaining battery runtime. This metric is absurdly inaccurate, even though I did a “calibration run”, including a full charge and discharge cycle. Being in IT long enough means I’m skeptical towards any kind of progress bar, but I never experienced a device under-estimating its runtime by 30%. That’s not terrible since I have a very consistent power usage profile, but it led to some suspicion about actual battery capacity and efficiency at the start. The battery will just continue to provide power with “0% remaining” for a couple of hours.
DC operations
Having a battery connected to a server and network equipment at all times raises a question: Why use alternating current (AC) at all? AC is provided by the grid, so many devices that run on DC have AC-to-DC converters at their PSUs. A battery natively produces direct current (DC) and a computer natively consumes direct current, this conversion mumbo-jumbo does not really make sense at first sight. Using DC would reduce the load of the inverter at the Delta 2 and also remove the need to have a traditional PSU at the server. Each of the output sections (AC, USB, DC) can be disabled individually, doing so helps to conserve power, especially the AC unit as it requires an inverter to run regardless of the output load.
Unfortunately, DC output is somewhat limited. The Delta 2 has a car-charger plug output which provides 12V DC at 10A max, not much but just enough to run my server and some network equipment directly off DC. I used a couple of XT60 connectors and a 80W PicoPSU for my server, and indeed that led to ~15% longer battery runtime. While the DC-DC PicoPSU is a lot more efficient at low load, compared to a 300W Seasonic PSU (~95% vs. ~85%), the DC-DC conversion within the Delta 2, converting from the battery cell’s combined 48V to 12V, does not seem to be super efficient. Perhaps that feature is not considered very important, but it’s quite disappointing to see 85% DC-DC efficiency while DC-AC is at 90%. I did not test the USB-C PD output since it would produce 20V at the required wattage and that needs to get converted down again, adding even more inefficiency.
There is another reason to avoid using the DC output on the Delta 2 - DC will always use the battery, while AC can bypass the battery while it is connected to the grid. DC usage will lead to small charge cycles that push the battery from 98% to 100% every couple of minutes, which will certainly have an effect on battery lifetime when doing so for years. It is very possible that all the benefits of DC-DC efficiency gets eaten away by this factor. Since I have to use the inverter anyway for the freezer and the POE Switch, I dumped the idea of using DC directly from the battery.
Final thoughts
With manual and automated energy consumption changes, we were able to dodge most of the price crisis. Using a flexible rather than a fixed price tariff can cut both ways, and one definitely needs to have the means (aka. idle cash) to endure a bad month. I’m convinced it is the right way to do over the long term, as it changes consumption incentives. With enough home automation in place, there are a number of optimizations that can happen without affecting quality of life.
Using a battery buffer to scalp cheap energy may seem to be a bit extreme, but when you play with the idea of owning a powerstation anyway, it’s certainly a consideration. The alternative for me would be a rather expensive gadget that sits on the shelf until it needs replacing. Those modern LFP-based powerstations are super useful for camping or backup power, quite a development compared to the NMC age.