Looks like they finally managed to solve the vulnerability. As far as i can see the shop system has been replaced or migrated with the one in use at their US and international shops. Apparently the old system was broken by design and beyond fixing. Great to know that issue is solved now, very sad to known that it took about a year and no mitigations were applied.
Customer Data For All Mankind

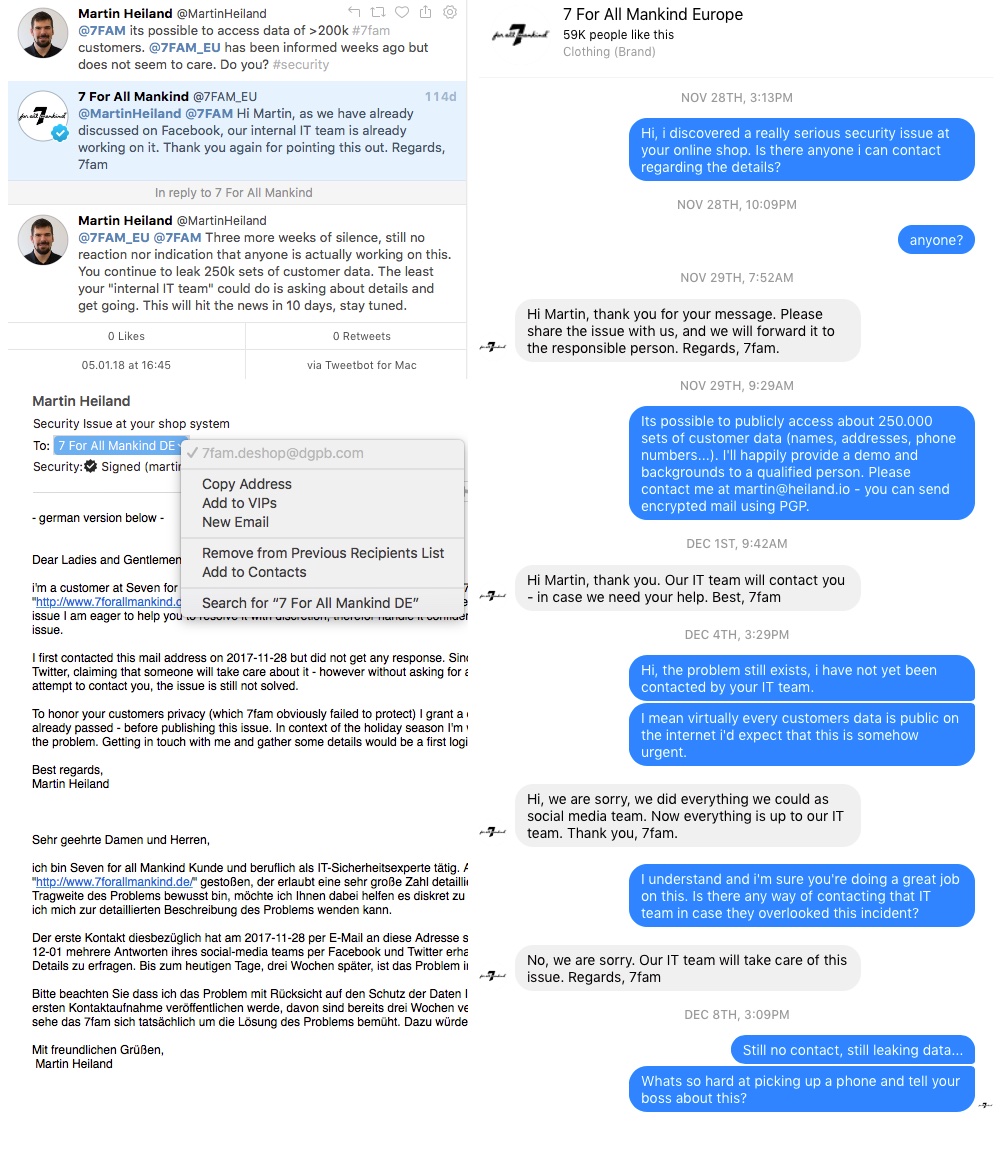
“7 for all mankind” (7FAM) is a California based brand that sells premium denim wear world-wide. Besides less severe issues with their online shop, they expose sensitive information about their clients like addresses, phone numbers and order details publicly. The flaw was found by chance while using their online shop as a customer.
I will not take credit for any fancy research, anyone could have found this - starting with 7FAM testers, operators and auditors. The overall experience with this case makes it very clear to me that there are no business processes in place to avoid and handle incidents like this. The company appears to primarily consist of marketing, sales and customer service. I run a bug bounty program myself and don’t expect response times like an IT company that deals with vulnerabilities on a daily basis. However, the actual response besides “oh, thats unfortunate” was effectively zero. I don’t blame people for doing their jobs but i am very disappointed by the organization failing to create any awareness.
Disclaimer
7FAM was informed back in November of 2017 and I offered to pinpoint and eventually stop the leak. Although communicating on multiple channels i never got any response indicating that someone takes action or at least cares about the topic. Apparently protecting customer data and IT systems in general has no priority for 7FAM and their security strategy is to kick the can down the road. Since the issue was reported half a year ago and is trivial to find, i decided to publish information although the issue is not fixed to date.
My hope is to get the attention of someone within the organization to take this serious since bad guys have or will potentially discover this flaw anyway. At the same time i feel sorry for those individuals which data got exposed by a weak security concept and even worse “management” by 7FAM. At several occasions i mentioned that i will publish this issue six WEEKS after calling it in. Now, after six MONTHS i run out of patience.
Disclosure timeline
- 2017-11-25 Discovery of the flaw, created demo script
- 2017-11-25 Attempt to established contact (Mail) no response
- 2017-11-27 Attempt to established contact (Twitter) no response
- 2017-11-28 Attempt to established contact (Contact Form) no response
- 2017-11-28 Attempt to established contact (Website Chat) no response
- 2017-11-28 Attempt to established contact (LinkedIN) no response
- 2017-11-28 Attempt to established contact (Facebook Messenger) no response
- 2017-12-01 First response by 7FAM via Facebook Messenger, rather useless
- 2017-12-11 More useless responses via Twitter
- 2017-12-16 Telephone call with customer service
- 2017-12-17 Several E-Mails to a address given to me, no response
- 2018-01 Many more E-Mails with customer service, got responses but no action was taken
Overview
When you order something at 7FAM online shop, you create an account, set a password and get access to your customer area. Then when purchasing, you get a mail confirmation and later on a receipt with a link to an invoice. Your order appears to be safely accessible through your customer area, however this is not the whole story.
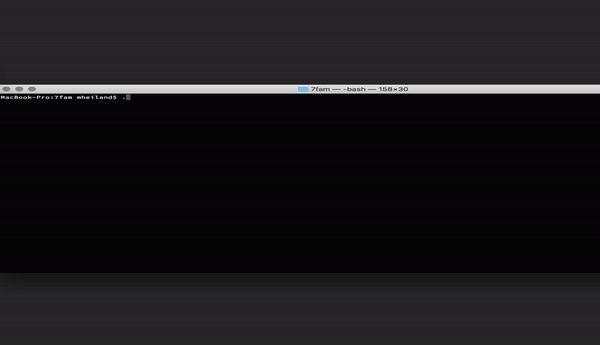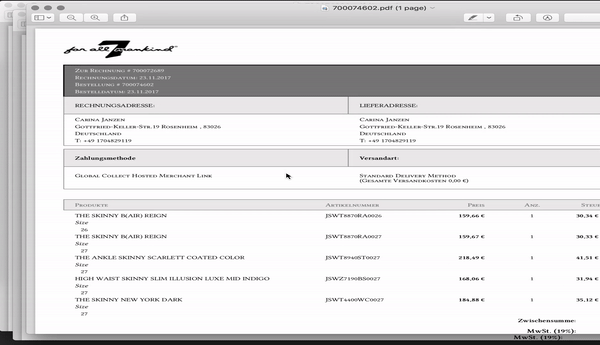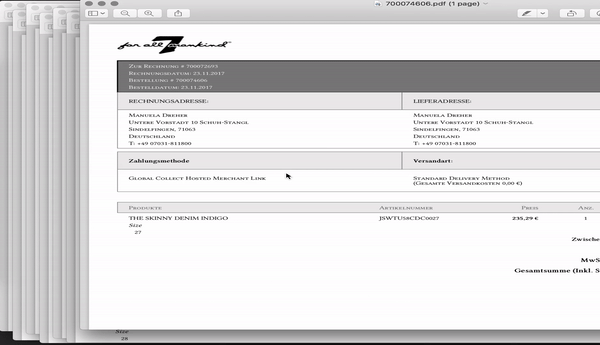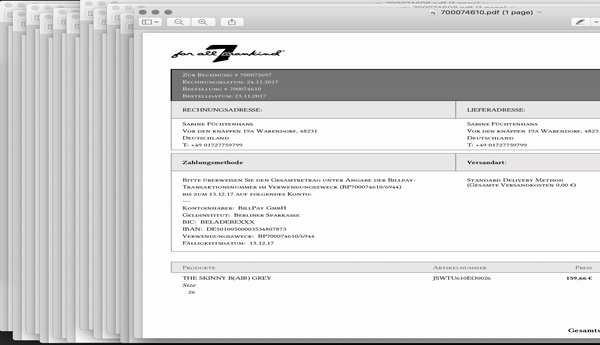
For whatever reason, 7FAM undermines their “customer area” and offers a PDF version of each invoice without authentication. I noticed this when clicking the “download PDF invoice” link at their mails and wondered: “Wait a minute, i logged out - why can i still access my invoice?”
Taking a deeper look made it clear that the “Download invoice” link does not contain any one-time token and not even a pseudo-random path which would make it harder to guess. In fact, every invoice gets an identifier and - yes you have guessed correct - this is an incrementing number.
Now the fun part starts, its not just my invoice which i can access, but rather every invoice of each online purchase made at their european online store since 2011. Ugh! Needless to say that there is no rate limit, expiration or other countermeasure to slow down access to invoices.
So i wrote a script and tried some combinations of identifiers. I ended up with a list of all valid countries and range of invoices. In total, 7FAM publishes about 250.000 invoices.
Playing with numbers
A typical 7FAM order ID looks like 700012345 - sorry Ruth, please complain at 7FAM.
The first part 70 is static and identifies the country at which the purchase was made, for example:
- 70 (Germany)
- 60 (UK)
- 11 (France)
The second part 0012345 is the unique and incrementing order identifier.
When downloading the invoice, a URL like this is called:
https://www.7forallmankind.de/de_de/sales/pdf/pdfinvoices?order_id=000000000
As a fun fact HTTPS is used to secure data in transit, which is completely useless since there is no authentication. At least we can be sure that the invoice originates from the advertised source :-D
There are plenty of unprotected invoices out there, judging from the last valid invoice ID.
| Country | Amount |
|---|---|
| Germany | 75.000 |
| United Kingdom | 63.000 |
| Netherlands | 32.000 |
| Belgium | 21.000 |
| France | 14.000 |
| Italy | 6.000 |
| Ireland | 1.500 |
| Spain | 1.000 |
| Total | 231.500+ |
Impact
Now, asking the obvious: what could someone do with this? Such invoices contain personal information like address, phone numbers, payment and shipping data, gender, body metrics and financial capabilities. Taking the typical demography of 7FAM customers into account, this makes the leaked data very valuable for unsolicited advertising, data validation, data enrichment, identity theft, harassment and stalking. This flaw also provides insights to internal 7FAM sales metrics for the region.
One aspect is really ugly, which is stalking. There are a lot of sick fucks out there that would really like to get a list of wealthy women around them that wear size 27 skinny jeans. 7FAM just provides them this data and they even get a phone number on top. I’m quite sure 7FAM customers would agree that this is a major breach.
Despite being mentioned multiple times during conversations with 7FAM, their “Internal IT Team” did not ever contact me. Interestingly enough my requests to help and provide details were shut down with “IT is working on it” nonetheless. It’s beyond my imagination what they were working on while apparently not knowing anything about the leak.
This whole process is a sad prime example for how NOT to handle security incidents. Such things will not just go away and rejecting help without having any information at hand is rather pointless. Denial will not get you anywhere, its all about having the right means, knowledge and awareness within your organization. Not just because GDPR tells you to…
State of transport-level mail security
The story so far
Securing HTTP has luckily become a commodity over the last couple of years, even for mainstream sites which only did enable secure connections for authentication processes before, if at all. Browsers start to implement more features (HPKP, CSP, HSTS…) with even better usability and start to get rid of legacy protocols and ciphers. At this corner of the internet, the state of TLS looks really good and everyone feels great about green lock-signs. But whats about less obvious areas of secure communication?
E-Mail for example has seen lots of good initiatives to enhance security primarily with the goal of reducing Spam (DKIM, Greylisting, Domain validation…). Apart from that the situation still looks quite ugly. There are indeed options for skilled end-users to do end-to-end encryption using SMIME, PGP for mail clients and to use browser-based crypto or server-side solutions for webmail applications. However, these solutions are either too complicated or only cover niches. Ultimately users could do something to improve their security when sending mail, but there is no solution to demand receiving mail securely - while incoming mail represents the vast majority of John Doe’s mail traffic.
By design E-Mail - more specifically SMTP - depends on servers talking to each other. Clients (like Outlook, GMail or Apple Mail) submit their messages to the configured server and let SMTP figure out a suitable route to deliver the mail across the internet and local networks. This leads to a quite robust infrastructure but takes away influence on security if the user did not encrypt the message. There is no way to tell or define what route a mail will take and if those servers communicate in a secure way with each other. Even when running a well configured mail server yourselves there is always a chance that a incoming mail was transferred in plain-text between two other servers. The recipient can only figure this out after receiving the mail, which might have been compromised by then. Keeping in mind what kind of sensitive data gets sent around multiple billion times per day, this is really troubling.
Security vs. cost
Operators of larger mail services usually enable strong security features but the majority of smaller operators does not care as much. With an almost bullet-proof configuration, there is a huge chance of not being able to communicate to many services. For example, while GMail or Outlook.com may use top notch security, many mails are sent by non-public mail operators such like your bank, random businesses or small online-shops. These guys often have no clue about proper SMTP configuration or have to depend on ancient mail system configurations for the sake of compatibility. Having a substantial error rate, say 5%, when sending or receiving invoices, general purpose or business communication leads to high cost.
With this in mind, most operators chose to stick with a less secure but more compatible configuration. For the more security focused operators, this means they can’t remove less secure configuration, a classical chicken-and-egg problem. There have been some regional projects to raise security (e.g. “E-Mail made in Germany”) which however appear to exist for marketing purposes instead of establishing real security. The ridiculous name aside, this initiative just makes sure that the biggest consumer mail operators in a given country talk TLS to each other. Those popular operators had TLS for incoming and outgoing SMTP enabled anyway and such campaigns avoid to mention that the other 99% of operators don’t know or care.
Mails sent by humans via huge mail services are actually a minority, most are generated by automated systems. If your local lawyers office or hotel booking system sends data to GMail without encryption it does not matter that GMail and Yahoo talk securely with each other. Those major services simply don’t force encryption on incoming mails to become a commodity, instead they implement a good-enough configuration to avoid being blamed and seem to hope the situation will enhance by itself. This led to the obscene situation that nowadays cat pictures on the web are better secured than critical information transferred via mail.
Doing the test
Lets get into some practical examples. I chose to enable a secure incoming SMTP configuration only allowing commonly used ECDHE ciphers (which are expected to be “unbreakable” in the forseeable future) for my own mail server for a month and checked what kind of issues would happen. “Funny” enough, most practical issues affected financial institutions and large corporations. My assumption is that those guys have a tight corset of policies in place that suppress innovation or even keeping up with reality when it comes to secure configuration. Some examples of failed incoming delivery:
- Deutsche Post (DHL) - mx1.dhl.iphmx.com
- Vodafone (MMS service) - vgmmsyvr.mmslegacy.vodafone.de
- Paypal - mx1.slc.paypal.com
- Apple - msbadger0201.apple.com
- American Express - extmta1-new.aexp.com
In most cases the worst thing that happens is that mail does not get delivered. American Express (“AMEX”) is a little different though. The topic has been discussed with one of their “Senior Security Analyst Cyber Security Investigations” (so much for title porn) but did not lead to any real change. I guess two months after disclosing the issue to American Express and not getting any more response it’s fair to get the word out.
The AMEX situation
What AMEX like most financial institutions does is checking for geo-location, IP and other fraud relevant metadata when accessing a account. If someone successfully logs in from France and just 10 minutes later from Japan thats reasonable suspicious to block access. Good idea. They then send a some-digit “authentication code” to the account holders mail address as additional factor to authorize the login. The same happens quite often when accessing the same account simultaniously from mobile and stationary internet connections since the IP and geo-location information changes, which gave me the opportunity to do research without traveling.
When the authentication code is delivered, AMEX does not handle ECDHE ciphers for SMTP and delivery fails.
Dec 23 16:01:05 box postfix/smtpd[25349]: SSL_accept error from extmta1-new.aexp.com[148.173.96.86]: -1
Dec 23 16:01:05 box postfix/smtpd[25349]: warning: TLS library problem: error:1408A0C1:SSL routines:SSL3_GET_CLIENT_HELLO:no shared cipher:s3_srvr.c:1440:
OK, so no authentication code for me, sad. But wait!
Dec 23 16:29:16 box postfix/smtpd[30013]: connect from extmta1-new.aexp.com[148.173.96.86]
Dec 23 16:29:17 box postfix/smtpd[30013]: 1FBCDAE88B: client=extmta1-new.aexp.com[148.173.96.86]
Dec 23 16:29:17 box postfix/cleanup[30017]: 1FBCDAE88B: message-id=<UMS255338020161223042913.DEUDEUMSPWR0001.ENG-ALERTS@welcome.aexp.com>
Some minutes later the same MTA connects again and succeeds. So what happened? Did they fixed their MTA in the meantime and trigger a retry? Looking at the received mails headers suggests otherwise…
# Received: from welcome.aexp.com (extmta1-new.aexp.com [148.173.96.86])
# by mx.heiland.io (Postfix) with ESMTP id 1FBCDAE88B
# for <recipient@replac.ed>; Fri, 23 Dec 2016 16:29:16 +0100 (CET)
The absence of TLS information at the header indicates that AMEX indeed has a fall-back for failed mail delivery - but one which drops any kind of encryption. This means my second factor to validate legitimate access to my credit-card account just got sent through the internet as plain-text since outgoing AMEX MTAs are incapable of handling 2015-ish security configurations. Ugh.
So what could be done with that? At the very least it makes passive attacks and sniffing shared networks a viable option to acquire this secure token. Some attacker could look out for reasonably secure mail servers to which AMEX is incompatible to and look out for re-tried unencrypted mail without launching an active man-in-the-middle attack. This might be a hard thing to pull off between AMEX and GMail, but certainly when thinking about smaller corporate mail services. Legitimate recipients may not notice the issue since they still get their authentication code, just a bit later. AMEX is quite huge in the corporate credit-card business so there is a good chance to hit some high-profile accounts with interesting data. I did not get into more detail with this but there certainly are some scenarios where this issue degrades passive security for the authentication code to near-zero. AMEX is just the example that came to my attention, there is no reason to believe this would be a unique case.
Lessons leaned
So what are my results from this one-month experiment?
- Using current generation encryption for SMTP leads to failed deliveries.
- It does not only affect small but also large companies. Public mail providers were unaffected.
- Forcing high security standards may even lead to drastically reduced security.
Folks, please fix your MTAs.
HPKP done right
Introduction
HTTP Public Key Pinning (HPKP) is a mechanism to make sure a HTTP client (e.g. web browser) only trusts a pre-defined set of certificates when establishing a TLS (“https”) connection. If the certificate presented by the server does not (or no longer) match the previously defined hashes, the connection does not get established. This is useful to counter man-in-the-middle attacks where someone intercepts the connection and in cases where DNS records or the certificate gets compromised. HPKP information is provided as a HTTP header with a list of hash values of certificate fingerprints as content. The client then checks the certificate used for the TLS connection against this list and will only trust the specified list of certificates for future connections to the domain. This highlights a important detail: Since HPKP operates on HTTP level and certificates are exchange on the (lower) TLS protocol level, the first connection to the host will not check for certificate fingerprints since the client does not yet know about them or the fact that the server offers HPKP. This also means there is no way to tell the client that a HPKP setting has changed prior to establishing a TLS connection and talking HTTP.
While HPKP is useful to enhance security, it’s a two-sided sword as well. Incorrect configuration may render your domain useless if clients look for the wrong certificate fingerprint. HPKP information is usually preserved by the client for two months or longer before getting refreshed. While clearing a clients history or settings will force a reset, there is no way to communicate this to users since the client will not even try to establish a HTTP connection. Worst case, the domain won’t be valid to serve content for the defined refresh interval. That being said, careful selection about what gets “pinned” at the header information helps to avoid most of the trouble.
The header is designed to contain a number of base64 encoded hash values which are valid for the specific domain and includes an obligation to pin “backup” hashes in case the “primary” hashes do not match anymore. A client will just iterate through the full trust-chain for provided certificate and look if any certificates fingerprint matches any of the hashes provided by HPKP headers. If any certificate matches, the check passes and the TLS connection is established. Now, what should be pinned at HPKP headers? The obvious answer would be “the certificate!” but wait - certificates may change quite often, especially when using short-living validity like Let’s Encrypt does. In this case the new certificates hash is not yet part of HPKP information stored with the client but the old one is expired, as a result the client would not be able to connect until the client re-requests HPKP information. More information can be checked at RFC 7469.
Primary hashes
Lets start with the “primary” hashes. Adding the hash of the domains certificate will certainly not harm, however that means the header information needs to be updated as soon as a new certificate gets issued for the domain. Next should be the Intermediate certificate(s) of the CA in case the CA uses them, this means any other certificate for the domain issued by the CA and signed with the same intermediate certificate will be valid for the host. Third is the Root certificate of the CA itself, which means that any certificate issued directly or via any Intermediate certificate by the CA would be trusted as well. Taking Let’s Encrypt for example, the following certificate hashes would get pinned:
- DST Root CA X3
- Let’s Encrypt Authority X3
- Domain certificate
Great, now what happens if your domain certificate expires and “Let’s Encrypt Authority X3” or the “DST Root CA X3” go out of business or get banned from the clients trust stores (hello WoSign, hello DigiNotar…)? The client would not accept any of the certificates because they are either removed from its trust store (Root, Intermediate) or not covered by HPKP information (new domain certificate). This is where pinned “backup” hashes come into play.
Backup hashes
Since there is no limitation in hashes, except the 8192 bytes limit for HTTP headers, it’s possible to pin hashes of Intermediate and Root certificates of other CAs which may be an option in case your primary CA gets into trouble. The next best thing to Let’s Encrypt might be Comodo, which means pinning Comodos Intermediate certificates or their Root CA in addition to Let’s Encrypt would flag their certificates to be valid as well.
There is another way though. Since what we’re pinning is not the hash of the actual certificate but the “SPKI Fingerprint”, we can also pin fingerprints of one or more Certificate Signing Request (CSR) which are not yet issued as a certificate. With this, a future certificate issued for this CSR is already pinned, regardless which CA signs the certificate. So in case of a problem with the current CA, that CSR is used to create a certificate at an arbitrary other CA. The certificates fingerprint would then already be part of the HPKP information since it matches the CSR fingerprint.
Creating hashes
HPKP transfers the SHA256 hash of the SPKI fingerprint of a certificate or CSR, generated with OpenSSL and no other hash algorithms are supported.
Certificate hashes
When pinning a CAs root or intermediate certificate, the first step is to acquire the correct public key. Usually CAs offer support pages where those can be obtained. The information about which root or intermediate certificates are used, can easily be looked up from the domain certificate, for example by inspecting it at a browser.
In this case the “DST Root CA X3” is the CAs root certificate and “Let’s Encrypt Authority X3” is a intermediate certificate. Searching for those names leads to the download page https://letsencrypt.org/certificates/ where the public keys can be downloaded as PEM format.
Creating the SHA256 hashes for the CAs root or intermediate certificates SPKI fingerprint is quite straight forward:
1 | $ openssl x509 -in lets-encrypt-x3-cross-signed.pem -pubkey | openssl pkey -pubin -outform der | openssl dgst -sha256 -binary | base64 |
The same command can be applied for the actual domains certificate:
1 | $ openssl x509 -in /etc/letsencrypt/live/heiland.io/fullchain.pem -pubkey | openssl pkey -pubin -outform der | openssl dgst -sha256 -binary | base64 |
CSR hashes
To create a CSR and a hash of its SPKI fingerprint, a private key is required to start with. Both the private key and the created CSR must be stored at a safe place for future use. The hash of the CSRs fingerprint can be used immediately for HPKP though.
Create private key
1 | $ openssl genrsa -out backup1.key 2048 |
Create CSR for single or wildcard domain name
Note that CAs may require or check the provided data of a CSR, for example the legitimization of the specified organisation or address. At the very least however, the “Common Name” is critical since it must contain the domain name for which the certificate will be created for.
1 | $ openssl req -new -sha256 -key backup1.key -out backup1.csr |
Create CSR for SNI
In case our certificate should contain multiple domains at its Server Name Indication (“SNI”) information, the default OpenSSL configuration needs to be tweaked a bit. The following additional parameters are required for the OpenSSL configuration file which comes with Debian GNU/Linux.
1 | $ cp /etc/ssl/openssl.cnf backup.cnf |
The the configuration file gets included when creating the CSR.
1 | $ openssl req -new -sha256 -key backup1.key -out backup1.csr -config backup.cnf |
Create hash from CSR
With that done, a SHA256 hash of the CSRs fingerprint gets created to be used as HPKP information. The command is equal for SNI and non-SNI CSRs.
1 | $ openssl req -pubkey -in backup1.csr | openssl pkey -pubin -outform der | openssl dgst -sha256 -binary | base64 |
HQZ03DioNrXVV7/zEuQONyO8cwUo3ncA71fzLO+o/d8= is the base64 encoded SPKI fingerprint of the CSR.
Creating the HPKP header
The header is a quite straight forward list of hashes and adds max-age information to define the maximum time a client (e.g. browser) will cache HPKP information once it got provided. This sample pins the CAs root certificate, two intermediate certificates and several CSRs as backup. The client will validate the presented certificate against all entries at this list, regardless of its order. Maximum age should be set to two months (expressed in seconds) or longer.
HTTP Servers like nginx allow to simply add those headers at the respective sites configuration:
1 | $ vim /etc/nginx/sites-enabled/martin.heiland.io.conf |
Testing
General availability of the header can be checked by using a browsers development console and look for response headers. There are some more sophisticated sites that check syntax, content and validity of that headers information
Before deploying to production, HPKP settings need to be double-checked since they may lead to unavailability of the site in case their content is incorrect. If the syntax is wrong, a client may just ignore the header and not add any security.
UniFi may Open up your network
Be aware when updating UniFi Controller from 5.3.x to version 5.4.x and running WPA Enterprise secured wireless networks. There is a good chance that your network ends up completely unprotected while to the administrator everything looks fine. Both versions are official “stable” releases, so there is a good chance lots of networks get affected.
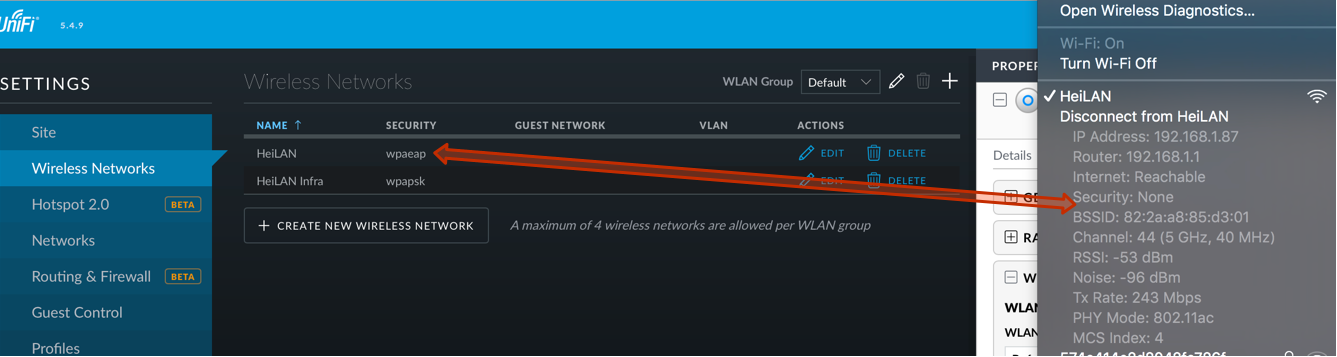
Reason for this appears to be the addition of “RADIUS Profiles”, more specifically the migration of existing settings to this profile. Prior to 5.4 each WLAN could have one RADIUS server assigned for authentication and VLAN assignment. The update to 5.4 appears to be faulty in a way that the old RADIUS information gets lost and no profile gets created. Once the APs fetch that new configuration, for example when restarting, they get a “null” value and fall back to “Open” security configuration. Yeah right, from “WPA Enterprise” to “Open” just by updating your controller! On top of that, UniFi Controller does pretend that the network is still “wpaeap” secured, so if you’re running a remote WLAN site you may not even be aware of the fact that anyone can access your network without authentication.
To identify the issue, check the actual WLAN settings by scanning the network and second look out for the following log-file entry at UniFi Controllers server.log file.
[2017-01-18 23:41:30,160]
I contacted Ubiquity Networks about this and they seem to be aware of the issue. However instead of accepting it as a massive vulnerability they just claim it to be “just a bug at the update”. UBNT likes to play at the Software Defined Networking (SDN) league, sensitivity for security issues at the “software” part does not seem to be a priority though. Lets see how quickly this gets handled in a serious way once some company networks unexpectedly “Opened”…
Let's automate Let's encrypt
Just in case you did not yet hear about “Let’s encrypt”, let me explain the context in a few words. Feel free to visit their website for more details. They’re starting their public Beta as early as 2015-12-03.
What is it about?
Services like websites are offering secure connections to ensure privacy. Protocols like HTTPS are used which require SSL certificate(s) and a private key to encrypt data in transit. Besides enabling encryption, a certificate makes sure you’re communicating with the service you intend to communicate with and not with someone who is intercepting your communication. Sending encrypted data to someone who can de-crypt it but is not the intended recipient is even worse than communicating in plain-text.
Certificates are signed by a certificate authority (CA) which acknowledges that the person which uses a certificate exists and is trustworthy. This is usually determined by checking the services domain via E-Mail validation or the person/organisations existance by checking paperwork. Software like web browsers use a predefined directory of trusted CAs to determine if they trust the judgement of a CA. For example, if Firefox trusted “Cool CA Inc.”, then certificates signed by this CA are also trusted and if i have a certificate signed by this CA, your browser trusts the connection to my website.
Since it’s quite hard and expensive to be trusted by all browser vendors only few CAs are trusted by default. Browser vendors obviously have to make sure that they can trust a CA since their judgement will affect millions of users. CAs which made it that far compensated their effort by making a fortune out of a technically trivial process of validating persons/websites and create certificates. That said, they’re also offering insurrance services but that’s rather irrelevant for most users. Taking money to enable security contradicts the general requirement of secure communication for everyone. Someone running a small website may not be able to invest a lot of money to get a SSL certificate signed by one of those CAs. One alternative would be using self-signed certificates which are not trusted by browsers and produce severe error messages when opening the website. Another alternative would be not to use encryption at all, which sadly is what many people have chose.
Let’s encrypt
This is where “Let’s encrypt” joins the party. They’re a non-profit organisation backed by organisations like Mozila, the EFF and some well established online companies. The organisation offers certificate signing for free and those certificates are trusted by all major browsers. You can find out a lot more information and details at their website.
A speciality of “Let’s encrypt” is that you can request certificate signing in a automated way and also renew your certificates this way. This is done by running a software which takes care about the request and signing process. Renewing is a standard process which usually needs to happen about every 1-3 years. Certificates are bound to a specific domain and domain ownership can change over time. Therefor unrestricted certificate validity for a specific domain can become a threat because they’re not validating the current domain owner anymore. “Let’s encrypt” wants to make sure this problem is very temporary, therefor they opted to make their certificates valid for 90 days. After or before that expiration date you need to renew the certificate and prove that you’re still owning the domain.
Automatically renewing certificates with ones that are valid for another 90 days is a big relief for webmasters that no longer have to run through a manual process. It’s a common issue that a certificate expires without notice and website visitors are getting error messages, this also gets solved by automation.
Automated renewal
So how to automate the process? “Let’s encrypt” offers a software to fetch/renew certificates and also validate if you’re still owning the domain. For that, the software needs to run on the server defined by the DNS entry for the specific domain. The software initiates the validation process (ACME) and a web service at “Let’s encrypt” communicates with that software. During that process ports 80/tcp and 443/tcp are used by default which means your webserver needs to go down for a couple of seconds to allow the software to use those ports. That downtime may be worked around in the future but for now i don’t care much about it. “Let’s encrypt” is working on integration with major web servers such as Apache or Nginx to make the process completely transparent. Until then some scripting is required, which i’d like to share.
To use automatic renew, first make sure your web server (nginx in my case) loads certificates from the letsencrypt folder.
1 | ssl_certificate /etc/letsencrypt/live/martin.heiland.io/fullchain.pem; |
Stop the web server and initiate the renew process. Note that a few options need to be set to force non-interactive renewal:
1 | $ service nginx stop |
Note that due to a bug, this command may fail several times with a “The client sent an unacceptable anti-replay nonce” error. In this case, just repeat the command until it succeeds.
If HPKP is used, you will need to refresh your pins:
1 | $ openssl x509 -noout -in /etc/letsencrypt/live/martin.heiland.io/fullchain.pem -pubkey | openssl asn1parse -noout -inform pem -out public.key |
Finally, restart the web server and check if it’s serving the updated certificate:
1 | $ service nginx start |
You obviously can put this process to a monthly cronjob, but you might to supervise the process a couple of times to make sure it works flawlessly.
Spy my Mac
Apple Inc. builds great computers. Well, at least the hordes of slave workers over at Asia do. Kudos to them for building astonishing precision and the design team to create beautiful machines that feel great when working with them. Shame on this $500bn+ company for taking advantage on such cheap labour, spending .5% of their margin on working conditions would provide hundreds of thousands of families a much better perspective and fair work. But lets put that aside for a moment.
A Mac can easily be sold for over 60% if its initial price two years from now. Try this with an Asus, Sony, Acer, HP, what have you. Almost all other Laptops i’ve seen so far - since IBM dumped the Thinkpad - look like a piece of junk after two years of transportation and serious usage (like 8-12 hours a day)
Now this is where the issue starts: Macs are re-sold regularly and people are trying to get their hands on a pre-owned device to cut some of the initial cost. On the other hand, Apple has built the perfect golden cage for it’s users. Services, hardware, software, complementary products - all very well integrated and made to work with each other quite smoothly (well, most times at least…). When buying a Mac, one does not just buy a computer but enters the realm of multiple services spun around the users “digital lifestyle” that tries to keep the user at the chosen platform. While hardware may and is meant to become obsolete, these services stay and are assigned to a user (via it’s Apple-ID) rather than to a specific piece of hardware. Obviously Apple is very successful in retaining users to proprietary services so they won’t flee back to good ol’ Windows or Android world.
One service that is tightly integrated with many Apple devices, is “Find My iPhone/Mac” (FMI from now on). In a nutshell, it geo-locates devices that are registered with the users Apple-ID in case a device got lost. This works for both phones/tablets by using GPS tracking as well as Laptops using wireless network information for approximate location. The service becomes very valuable over time and more than once it helped to give a good idea on where i’ve left my phone. Other than locating a device on a map it allows basic remote management features like making the device audible, lock it to avoid misuse and wipe it’s data in case it got potentially compromised.
Now, what’s the catch? Well, back in 2011 i bought a MacBook Air and used it for almost two years before selling it online. While using it, i had FMI activated and the device has been assigned to my Apple-ID. Also, i enabled FileVault which is an encryption feature of OSX that encrypts the whole computer storage, which by the way everybody should use. Additionally i’ve wiped all of that storage data to hand over a plain computer to the new owner. There is close to no chance that anybody outside of an intelligence agency or Apple could access my old (account) data. I sold it to one of these fixed-price dealers where you don’t get to know the buyer nor care about what happens with the machine.
Roughly half a year after i sold that machine, i occasionally checked by FMI to see if there have been updates to the service. To my astonishment, a machine called “Luisa’s Mac Book Air” showed up at my list of machines.
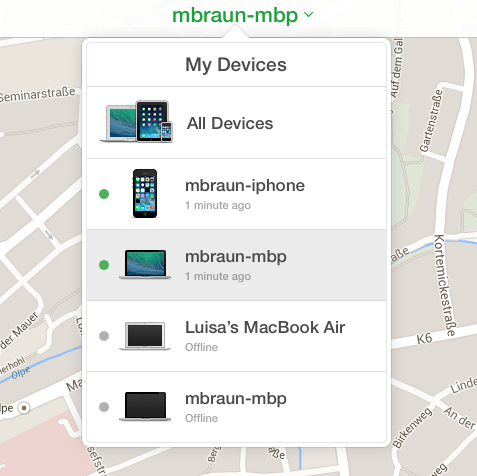
It was not online at the time i checked so i opted for “Notify me when found”. Shortly after, i received an E-Mail. My old Mac Book Air has been found. Yay! Interestingly enough that it has still been linked to my Apple-ID, all the location and remote management feature were still in place. Based on the location information and her name used to generate the computer name, i was able to look up Luisa on various online services. She’s a student and based on the transportation habit of her (my old) Laptop it should be easy to find out where she’s living, whom she’s meeting and what courses she’s taking… Well i’m not interested in stalking people so i took this much information to verify it’s real. Given a bit of criminal energy, i could lock her machine and blackmail her to re-gain access to her data. Not interested in this as well, just sayin’.
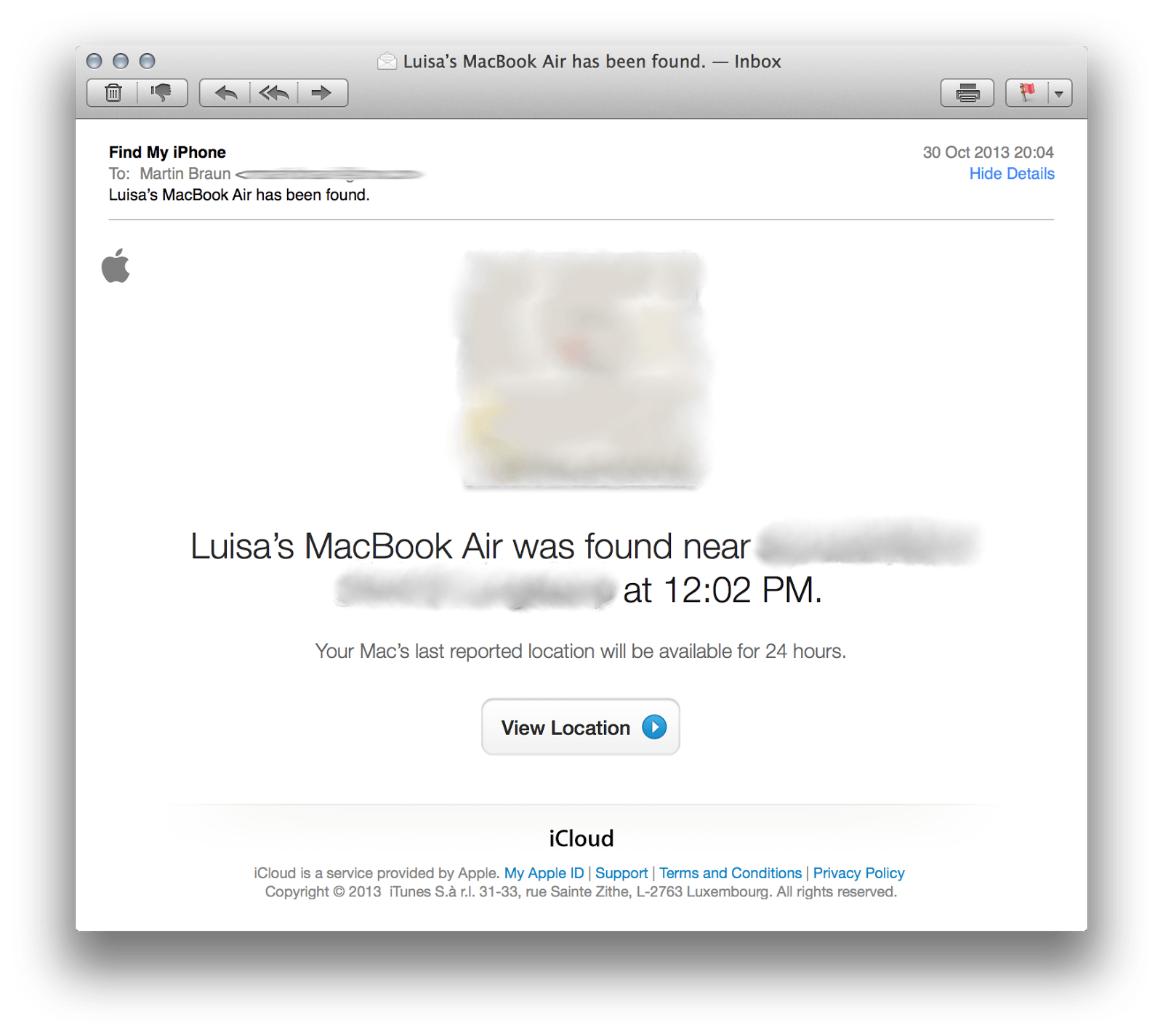
There are stories of guys that recovered their stolen machines by hacking into it remotely, track it, identify the thief and all that stuff. Apple, pursuing the idea of “everything simple”, has just taken it a step further. In a nutshell, i got privileged remote access to a machine that has been wiped-clean, re-installed and i had no user account nor information about. Well, that’s one hell of a privilege escalation. Luisa for sure is not using my Apple-ID and has no clue that she can still be tracked.
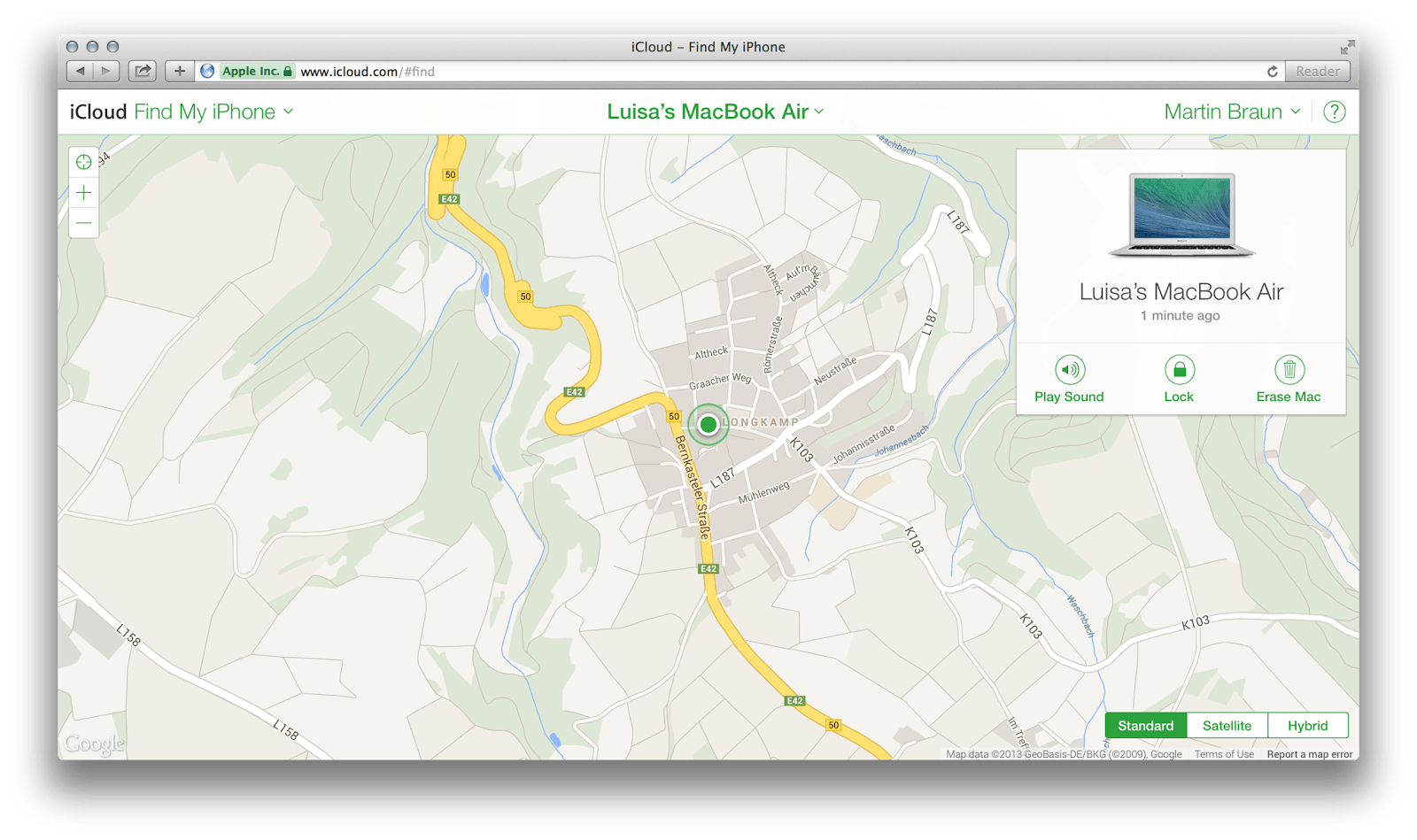
There are various scenarios on what has happened. She uses FMI and all that iCloud stuff, that would point out a permission issue within iCloud when linking machines to Accounts. Or, she does not use FMI, which is worse since it implies this service is available regardless of the users choice made when setting up the machine. In both cases the new owner of the machine does not seem to have any possibility to opt-out from being tracked by the previous owner.
Digging deeper, i started to suspect that Apple is not really using the owners user or account credentials to get access to the machine. While this may be a logical implementation to track/manage machines where the user is not logged in, it’s quite critical in terms of privacy. A user may enter a strong password and connect the machine to it’s Apple-ID - but in the end it’s just identified and accessed by some kind of unique hardware identifier. At least the FMI web app uses such (hashed) identifiers. It’s a good guess that these IDs are used to bypass authentication at her Laptop. In this case, it is plausible that Apple has remote access to location data of all devices as well as powerful remote management capabilities (wipe, lock…). At the very least, remote access to the machine is not secured using credentials that the user has chosen at it’s Apple-ID but rather a static ID and vague trust-relationship with Apple. Authentication by shared secrets is an issue for itself, however it’s still better than obviously having no secret within the authentication process.
Now, i’ve contacted the Apple product-security contact and described the issue. The contact is very responsive, which definitely is a good sign for taking such issues seriously. However, they came back with the statement, that there is no actual security issue. I (as the previous owner) could just remove my old machine from my FMI account to stop tracking it. Well yeah, that may “help” me not tracking somebody - but it’s definitely not helping the person that gets tracked. Furthermore they pointed to a “how-to” document that describes what actions should be done before selling a Mac (e.g remove it from all iCloud services). This document of course is optional and the new owner has no way of verifying that the previous owner has removed the machine from these kind of services.
So what is this? Bad luck? Poor design? Wrong expectations? One could argue that if a machine gets stolen and logged out, the original user still needs to be able to wipe it. That’s true and valid, but does not require the machine to be bound to the original users Apple-ID for it’s whole lifetime. As soon as somebody wipes the storage or starts over using a different Apple-ID, the connection with FMI should be save to be reset. After all, FMI is not a thievery protection system, it’s a service to find a temporarily lost device. Is Apple doing this kind of hardware-service-lock-in to prevent users from reselling their hardware? Well that could be, but i don’t think they do it on purpose or to push their own “used hardware” service.
IMHO it’s a follow-up issue of the attitude to retain customers and all their credentials, data and devices to a closed ecosystem. This is just one more example where “simplicity over security” has a significant backlash. Also, it illustrates that open source software for infrastructure is not the only key to a more trustworthy and secure environment. Web services are already much more relevant to end-users than operating systems or infrastructure services are. Many of these underlying services have already become invisible. Trusting both web and infrastructure services with sensitive information like unrestricted access to physical location data is a huge problem if the service is running as a complete black box without the user in control of his or her own data.
There is a pressing need to discuss, spread and implement the definition of “who owns what” within the web services world. Right now, most people are extremely naive when blindly accepting these 70 page’ish TOS, since there is no real socially acceptable alternative to many of these services. Users must become sensitive to this an be in a position to claim their ownership on their data. Giving it away to industry giants for free will manifest the current situation and ultimately lead the way to a world with few players dominating not just the market but also their users habits and (digital) life.
HTTPS, Forward Secrecy vs. Compatibility
When talking SSL and HTTPS nowadays, the talk often goes about “Forward Secrecy” (aka. FS). Now, as Wikipedia perfectly explains what that is, there are basically two requirements that tend to conflict very often in politics, technology and every day life: Security and Compatibility. While it may be best from a security standpoint not to use a car for transportation, it’s quite an incompatible choice in many regions of the world. Same goes for SSL and encryption standards.
There are a lot of internet users today and many are using outdated technology. Based on the target group of your web service, you need to take these people into consideration, even if it means that most bleeding-edge and probably more secure standards cannot be used. It’s totally up to you what decision to take. For my personal site, i opted to force people using modern browsers and operating systems. If you run an online shop and care more about revenue than security or education of your visitors, the opposite decision may be fine for you.
While this is targeted to server administrators, there are quite a few ways for users to prefer more secure connections, for example by re-configuring their browser. For example, check out these german or english guides on how to remove RC4 usage from Firefox.
The provided configuration examples have been tested and implemented with Apache 2.4 and most current openssl - most Linux distributions won’t offer this yet so you may need a fallback to Apache 2.2 (and not use TLS1.2), switch to nginx or install packages from a different distribution flavour. OCSP stapling is also only available with Apache 2.3 or later. When working with any kind of SSL setting, please note that your users and your systems security depends on much more than just a potentially secure SSL link.
I am referring to some popular SSL testing services, however i think they’re not entirely accurate and a “80/100” rating does not mean that your server is insecure. Still, they are a good pointer and great for auditing the current configuration.
The first configuration mitigates the BEAST attack by not using TLS 1.0 as well as CRIME and BREACH by disabling SSL compression and it does not offer potentially broken RC4 ciphers. Note that since TLS 1.0 and 1.1 are disabled with this configuration, it will definitely cause compatibility issues. TLS 1.0 is the “gold standard” (read: legacy stuff everybody implemented) and almost every SSL enabled site uses it. SSLv2 and SSLv3 are definitely dead and should be avoided. TLS 1.2 is not as common yet, just the most recent browser versions do support it. Keep in mind that such settings will also keep some website crawlers from indexing your site and providing a less optimal SEO rating.
1 | SSLEngine On |
OCSP stapling needs to be configured outside of the “VirtualHost” scope. Note that the OCSP responder is usually provided by your CA. This is most likely not the case if you’re using self-signed certificates. The Strict-Transport-Security (HSTS) header signals, that the server only wants to talk via TLS/SSL and is used to avoid man-in-the-middle attacks on SSL.
1 | Header add Strict-Transport-Security "max-age=15768000" |
These settings will give you a Grade A 100-90-90 rating over at sslcheck.x509labs.com or ssllabs.com, however be assure that it’s not the most compatible setting. Connecting is possible with current versions of Chrome, Internet Explorer, Firefox and Safari.
The second configuration is more compatible to legacy browsers. However, it does not mitigate the BEAST attack since we have to stick with TLS 1.0 and 1.1 for compatibility reasons.
Not offering RSA+3DES as cipher did essentially kill off Internet Explorer on Windows XP so this cipher gets added in this configuration. Note that the order of ciphers is relevant to define their priority. Putting a potentially weak cipher first is not a good idea since it may lure browsers to a lower security level than they could provide.
1 | SSLProtocol +TLSv1 +TLSv1.1 +TLSv1.2 |
This will still give you a Grade A 95-90-90 rating and will work with all browsers. FS is used for every browser except Internet Explorer. Keep in mind that this configuration will not mitigate the BEAST attack on web servers.
Overall, there is no “perfect” SSL configuration for Apache. Especially the lack of TLS 1.2 implementations legacy clients is quite a PITA when aiming to offer secure connections. Compared to the default Apache mod_ssl configuration, even the “more compatible” SSL configuration discussed here is a step forward in security for clients that run current operating systems and browsers.