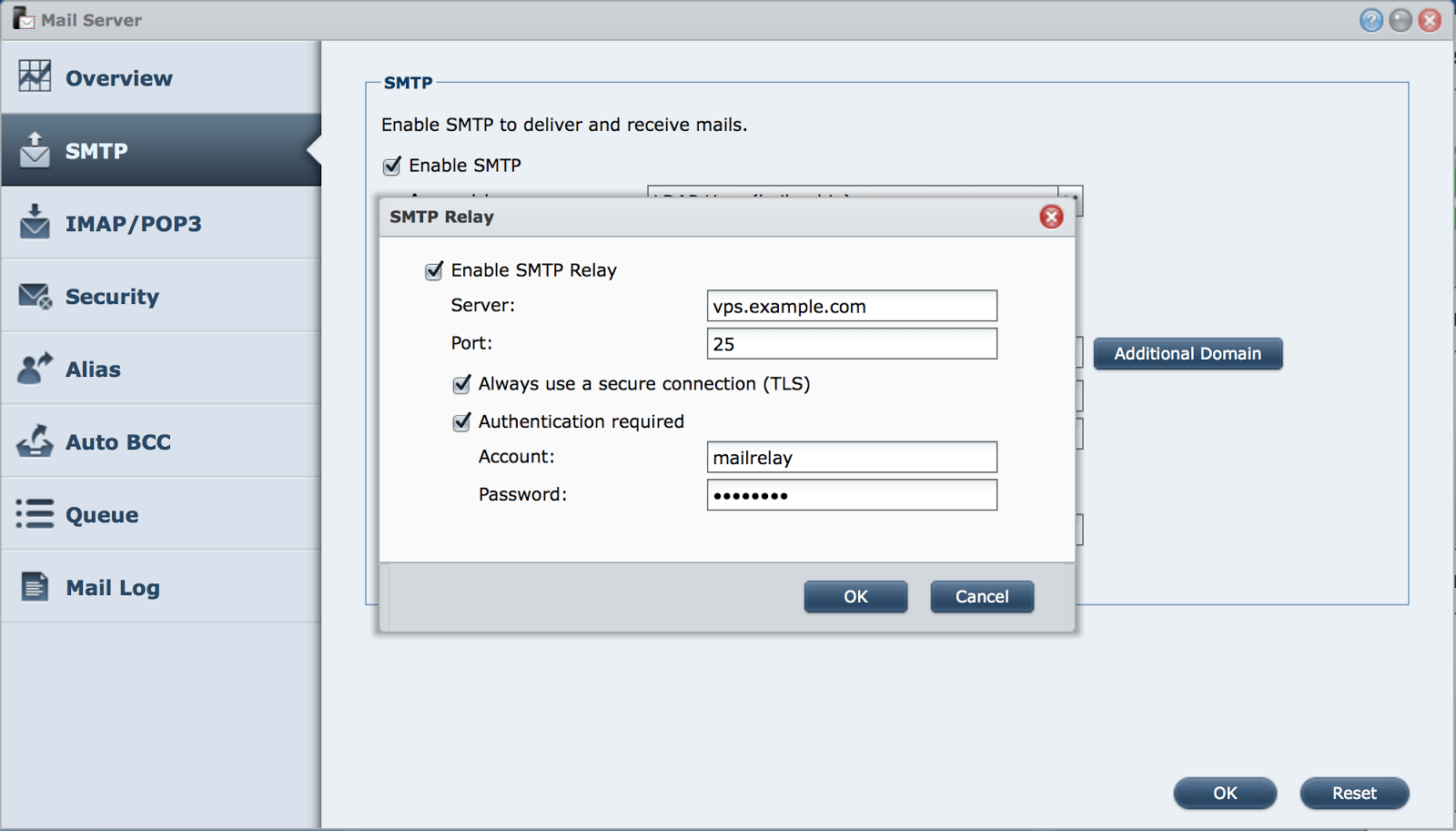
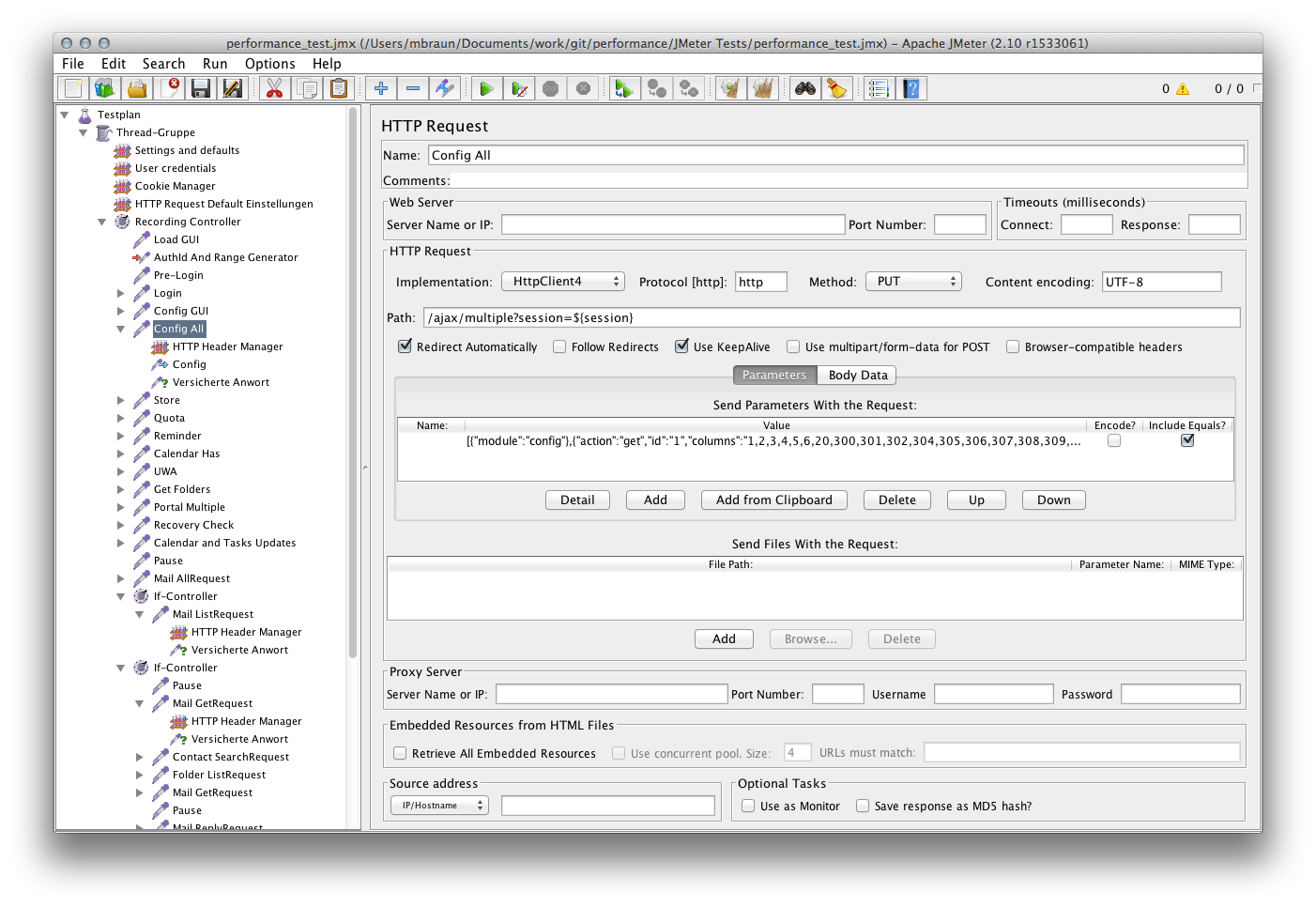
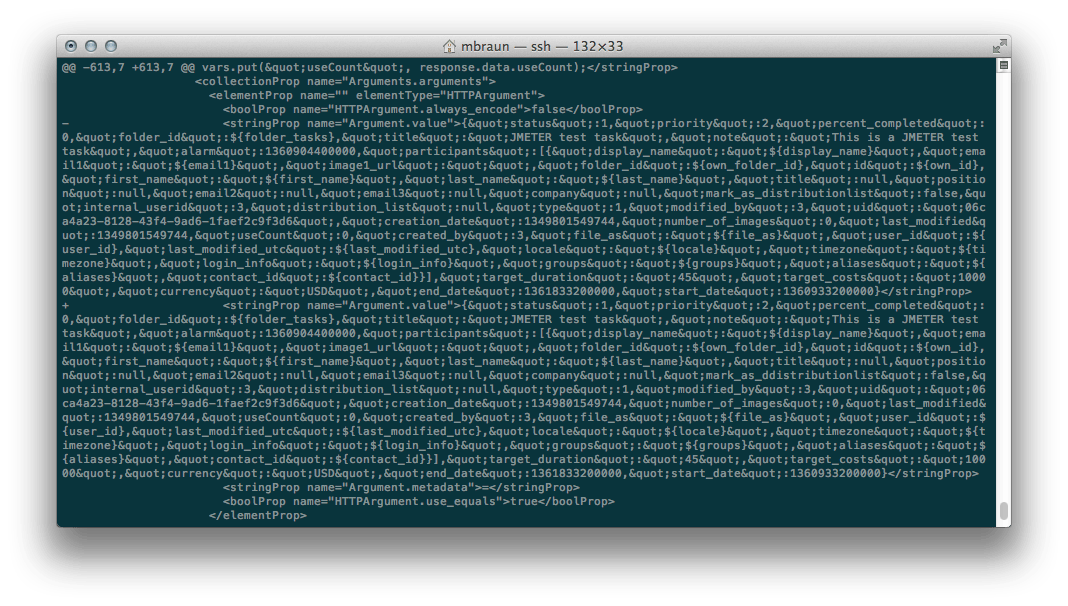
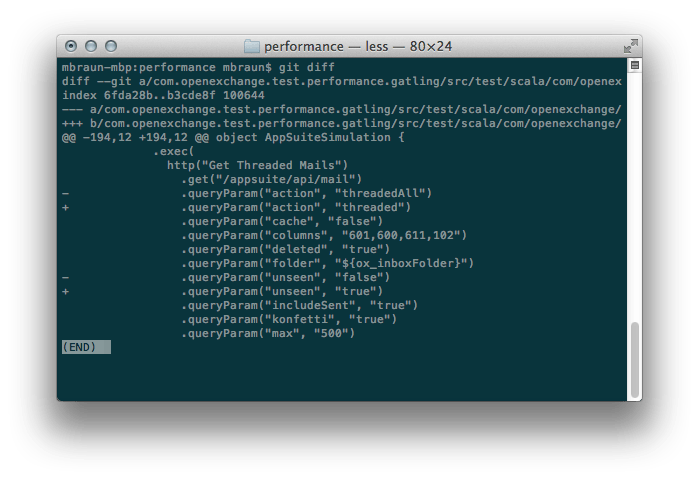
A while ago, we decided that our living room is occupied by too many remotes. While this is a common issue when building a HDTV/BD/ATV/Audio rack, the solution is plain and simple: Get a universal remote. I decided for a Logitech Harmony Ultimate which does have quite some track record in terms of building remotes. There are other manufacturers that build such remotes as well and please feel free to evaluate them. I sticked with Logitech since i already own(ed) some of their stuff and it worked well. Also, their system is widely used and a de-facto standard. I like the idea of a more-or-less simple remote and a “invisible” hub quite a lot.
The good
Not going into details or writing some product review, however the Harmony Ultimate remote and the hub are very well built. The touch screen is okay’ish regarding responsiveness and all buttons have a nice feedback and illumination. The tilt sensor is a very good idea to wake up the remote on movement. Overall i’d say hardware is a B+ since i dislike the idea of the LCD splitting the buttons and the hub is perhaps a bit larger than required. I also got a pair of Harmony Precision IR cables to directly attach them to the devices rather than placing the IR blasters. These guys take care of the rack which is now behind closed doors while the hub manages the HDTV and speaker setup.
The bad
Logitech opted to go a all-online configuration. Generally that’s a good idea to spare fiddling around with USB cables and software installation. The hub connects via WiFi and fetches the current configuration when being told to do so. Same applies to the Android/iOS remote app.
What i really dislike about this choice is, that Logitech requires a browser-plugin to be installed. Hell, the 90ies are over! Technically it does not seem to be more than a Browser-USB bridge for initial setup of the Hub and the remote. Apart from that, Logitech opted for a user configuration frontend built with Silverlight… While arguing on Silverlight/Flash/HTML/Java is quite exhausting, i simply state that i don’t like the implementation. It works without larger glitches, but feels quite slow and clunky.
Some very basic features are missing from the Harmony Ultimate: PIN lock of the remote and multi-user support. So in case you don’t want your kids to use the Harmony to play around, you have to hide it. A simple 4-digit PIN lock should not be rocket-science, eh? Even worse than that, you do have one online account at myharmony.com which is bound to your remote. Meaning that if you don’t want to share the credentials with your husband/wife/kids. On top, you cannot change the accounts mail address and your configuration cannot be exported. I’d really hope that Logitech accepts that there is more than one person within a typical household which wants to configure the remote.
The ugly
Apart from controlling some TV/Audio devices, i use a set of remote power outlets (Intertechno IT-1500) to shut down any standby activity of my TV/Audio rack. In order to do so, it’s mandatory to have a piece of hardware that’s compatible with your Harmony and your RF outlets. Harmony Ultimate does use IR and Bluetooth, no RF. In my case, i opted for the LightManager Pro+ which can handle my outlets and is compatible to most RF outlets offered in EU/Germany. This nice piece of hardware gets configured separately to communicate with your outlets. In the end, it offers 254 slots for RF devices and can assign several commands to each (on/off/toggle/dim) as well as time or even temperature based actions.
Integrating the LightManager to your list of devices and activities is quite straight forward since Logitech already knows the IR codes. But to my surprise, i simply could not do anything afterwards! I could customize my Activity and add a command for the LightManager, but it kept being added to the bottom slot of my activities command list. Of course i’d need it in #1 slot since all subsequent devices rely on power supply. Logitech states, that additional commands to an existing Activity must be added to the bottom of the list and that there is no way to re-order them. Damn!
After some quite friendly but not very productive calls to the Logitech support, i did take some time to work around the issue. As it turned out, there is a way!
Turning on outlets before turning on devices
I assume that LightManager is already configured and your remote outlet takes “L001” as “on” and “L002” as “off”.
First, go to the crappy Silverlight abomination which calls itself “MyHarmony” and login. Chose your remote and select “Devices”. Now select your LightManager and click “Change Device Settings” and go for “Power settings” and chose “I want to keep this device on… turn it off when i press the Off button”. This will help saving a lot of time when switching Activities that rely on the same power outlet. At the next step, tell Myharmony, that you use two different buttons for power on and power off. Finally, Myharmony lets you assign power on and power off actions. There, you assign command “L001” for power on and “L002” for power off. When you now add the LightManager to an activity, you can put your LightManager “power on” to slot #1. The downside is, that you need one LightManager “device” for each outlet you want to power on/off, but Harmony Ultimate can handle 15 so that should work out for post people.